Setup SQL data source for pivot table reports
You can configure a 'live' connection to your SQL database and use it as a data source for operational reports (pivot tables, charts, flat tables) .
Data is not imported: SeekTable executes aggregate queries SELECT .. GROUP BY on-the-fly (direct query) to load only necessary data for the concrete report.
There are no limitations on the dataset size; however, your database should be able to execute aggregate queries fast enough: ideally in seconds (up to 2 mins max). In case of moderate size fact tables - up to millions of rows - most popular DBs can do that. For large tables a dataset size can be limited by applying WHERE conditons on indexed columns (see parameters setup section below), or by usage of pre-aggregated tables / materialized views. For a real-time big data analytics (billions of rows, TBs in size) you can consider to use specialized columnar databases (data warehouses):
- built-in DuckDB engine
- cloud DW services: Amazon Redshift, Google BigQuery, MotherDuck, Snowflake
- self-hosted: ClickHouse, Postgres with DuckDB extension (pgduckdb), SingleStore, MariaDb ColumnStore, QuestDB etc
How SQL connector works
SQL-based cubes are defined with a fact table; for flexibility purposes it is configured as a Select Query template, so this could be a resultset returned by a view/function/complex SQL statement. Cube dimensions are mapped to columns (or SQL-expressions), and measures are SQL aggregate functions.
For summary reports (pivot tables/charts) SeekTable ROLAP engine generates GROUP BY queries in this way:
- Let's assume that cube's Select Query is simply
SELECT * FROM facts
- For a pivot table report with
column1andcolumn2dimensions on Rows/Columns andSum of column3measure on Values SeekTable executes this query under the hood:SELECT column1, column2, SUM(column3) FROM facts GROUP BY column1, column2
Hint: you can see the report's SQL query in View → Show Query dialog. In case of SQL error it is enough to click the "show database query" link (you should see it as a part of the error message). - If Select Query doesn't start with
SELECT *generated query will be:SELECT column1, column2, SUM(column3) FROM (<Select Query>) t GROUP BY column1, column2
A star-schema is fully supported: dimensions may be resolved with conditional JOINs, also JOINs may be inside Select Query and it is possible to include them into the final query depending on the report configuration (only when JOIN is needed).
How to configure a SQL data source
- Click "Connect to Database" at "Cubes" view, or just open this link (ensure that you're logged in).
-
Select "SQL-compatible database" in Data Source Type selector:

- In Cube Name enter short title that describes this data source.
-
Choose your database in Database Connector and configure its Connection String:
- MS SQL Server, Azure SQL
- MySql, MariaDb, SingleStore (suitable for any mysql-protocol compatibe database)
- PostgreSql, Amazon Redshift, QuestDB, Cube.js
- Oracle Database
- Google BigQuery
- Snowflake
- ClickHouse
- Presto/Trino
- DuckDBon-prem version only / MotherDuck
- Your DB is not in the list? It may be added upon request if it has ODBC driver.
-
Specify Select Query: this is a SELECT command that loads all possible columns for dimensions or measures.
In simplest case this might be something like:
SELECT * FROM facts_table_or_dataview
You can specify a complex SQL query here (with JOINs, WHERE).- use simple form
SELECT * FROM tableorSELECT f.* FROM table fwhen possible: this allows SeekTable to avoid wrapping the query with the outerSELECTand*will be replaced with actual columns needed for the report. - do not specify
GROUP BYunless you really want to work with pre-aggregated dataset - do not specify
ORDER BY, it will be ignored anyway - do not use
ttable alias, it is reserved for the outerSELECTgenerated by the reporting engine (used when needed)
- use simple form
- Keep Infer dimensions and measures by columns checked to determine dimensions and measures automatically by the first N rows. You can modify suggested configuration later.
- Click the "Save" button.
If everything is fine you should see a new cube dashboard with the list of available dimensions and measures.
In case of connection error you'll see an orange box with an error message; you may click "Edit Configuration" and apply necessary changes.
Dimensions setup
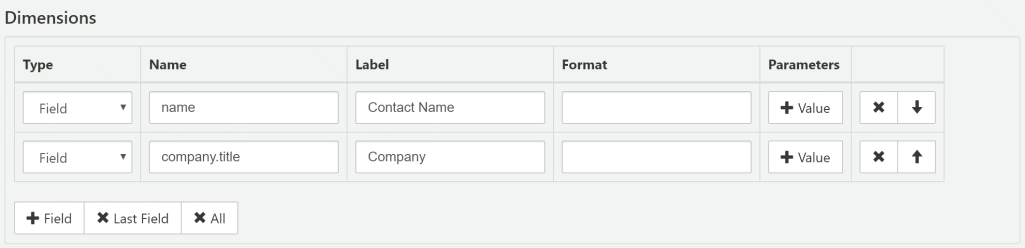
- Type
-
Field: dimension name refers to table column or result of SQL expression (can be provided as the first "Parameters" value).
Expression: dimension is defined as calculated field with custom formula that uses another dimensions as arguments (formula and arguments should be specified in "Parameters"). - Name
- Unique dimension identifier. For Type=
Fieldthis is column name specifier (possibly with table alias prefix). - Label
- User-friendly dimension title (optional).
- Format
-
Custom format template (syntax is for .NET String.Format, only zero-index placeholder
{0}can be used). Examples:prefix {0} suffix→ append custom prefix and/or suffix{0:yyyy-MM-dd}→ format date (or timestamp) as 2017-05-25{0:MMM}→ format month number (1-12) as a short month name (Jan, Feb etc){0:MMMM}→ format month number (1-12) as a full month name (January, February etc){0:ddd}→ format day-of-week number (0-6) as a short day-of-week name (0=Sun, 1=Mon, 2=Tue etc){0:dddd}→ format day-of-week number (0-6) as a full day-of-week name (0=Sunday, 1=Monday, 2=Tuesday etc)
- Parameters
-
One or more values with additional dimension's configuration:
-
For Type=
Field: you can specify a custom SQL expression for this dimension (1-st parameter), or dimension's ID column when dimension name refers to a column from "Conditional JOIN rule". Report parameters may be used in this SQL, in this way you can have a dimension that depends on the user-entered value(s).
Do not wrap dimension's SQL expression with excessive outer brackets like(<expr>)until you want to force special SQL generation mode which usesGROUP BY <ordinal>syntax for this particular dimension (this convention works only if DB supports this syntax). -
For Type=
Expression: you can specify formula expression (1-st parameter) and dimension names for the arguments (2-nd, 3-rd etc parameter).
-
For Type=
Measures setup
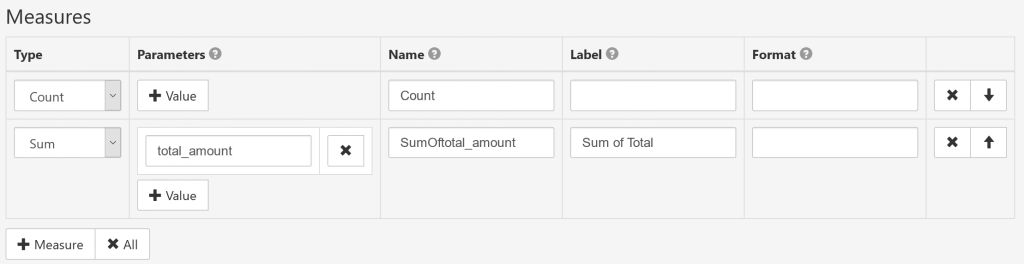
- Type
-
Count: the number of aggregated rows.
Sum: the total sum of a numeric column.
Average: the average value of a numeric column.
Min: the minimal value of a column.
Max: the maximum value of a column.
FirstValue: custom SQL aggregate expression; for example: 'COUNT(DISTINCT some_column)'.
Note: sub-totals/totals/grand-total will be empty for this type of measure because SeekTable cannot calculate them on its side. Most DBs can return totals with "GROUP BY CUBE" syntax, see How to enable totals for "FirstValue" measuresExpression: measure is defined as a formula calculated by SeekTable.
- Parameters
-
For Type=
Count: no parameters needed.
For Type=Sum/Average/Min/Max: a column name to aggregate (this can be a custom SQL expression).
For Type=FirstValue: the first parameter is a custom SQL aggregate expression.
For Type=Expression: the first parameter is an expression, and next parameters are names of measures used as arguments in the expression.
Report parameters may be used in custom SQL expressions, in this way you can organize a dynamic user-controlled measure. - Name
- Explicit unique measure identifier. You can leave it blank (for any measure types except "Expression") to generate the name automatically.
- Label
- User-friendly measure caption (optional).
- Format
-
Custom format template (syntax is for .NET String.Format, only zero-index placeholder
{0}can be used). Examples:{0:$#.##}→ format number as $10.25 (or empty if no value){0:0,.0#}k→ show number in thousands with "k" suffix{0:0.#|k}→ if number>1000 shorten it with "k" suffix{0:0,,.0#}M→ show number in millions with "M" suffix{0:0.#|M}→ if number>1000000 shorten it with "M" suffix{0:0.#|kMB}→ shorten large number with appropriate "k"/"M"/"B" suffix
Report parameters setup
Report parameters are used when you need to declare user-defined variable and use it in the SQL template as you want; typical usage is SQL query filtering with WHERE conditions.

- Name
- Unique (for cube) parameter identifier.
- Label
- User-friendly parameter caption for UI (optional).
- Data Type
-
String: text-based value.
Int32: 32-bit integer (max value is 2,147,483,647).
Int64: 64-bit integer (max value is 9,223,372,036,854,775,807).
Decimal: Fixed-point number with max 28 significant digits. Decimal point is '.' character.
DateTime: datetime or date value (in this case datetime value has 0:00:00 time). Date value should be specified as string in YYYY-MM-DD format.
Boolean: accepts only 'True' or 'False' value.
- Multivalue
- If checked parameter can accept several values (as array, in UI user can enter them as comma-separated string). Multivalue parameter can be used only with SQL IN condition.
- Default Value
- Defines default value of this parameter. Empty means 'not defined'.
- Expression
- Custom expression to evaluate final parameter value. Expression syntax is the same as in
calculated cube members; you can access user-entered values with
Parameter["param_name"].
When parameter is defined it can be used in Select Query as following:
SELECT * FROM orders o WHERE 1=1 @orderDate[ and o.orderDate>={0} ]
Parameter's placeholder syntax:
@- identifies that this is a placeholder for the parameter
orderDate- parameter Name
[ ]- SQL part between square brackets is added to SQL command when parameter is defined.
Optionally you may define an alternative SQL part that is used when parameter is not defined in this way:
@paramName[ expression_when_defined ; expression_when_NOT_defined ]
{0}- an inner placeholder for the parameter's value. This value is inserted into the SQL as a command parameter → SQL injections are impossible. This also means that parameter value cannot contain SQL expression or used to provide a part of SQL command (only exception is when parameter's Expression uses
Sql.Rawfunction).
Notes:
- multivalue parameters may be used only with SQL IN condition
SELECT * FROM orders WHERE 1=1 @countries[ and o.country IN ({0}) ] - Inside a placeholder several symbols have special meaning, and if you need to use these symbols in the formatting template they should be escaped in this way:
;→;;or\;
]→]]or\]
{→{{or\{
}→}}or\}
\→\\
@→\@ -
it is possible to use nested placeholders. For example:
@table_join_enabled[ LEFT JOIN table a ON (a.id=table_id @column_param[and a.column={0}] ) ]
Efficient lookups resolution conditional JOINs
Data in SQL warehouses is commonly structured using a star schema. This setup splits your data into two categories:
- Fact tables: the core tables containing your numeric metrics and foreign keys.
- Dimension tables: supporting (lookup) tables that hold the actual descriptive attributes used for filtering and grouping.
To resolve lookup values these dimension tables should be joined in the cube's Select Query, for example:
SELECT o.*, c.name as country_name FROM orders o LEFT JOIN countries c ON (c.country_id=o.country_id)
This setup works perfectly when your facts table (i.e. 'orders') is relatively small and queries run instantly. When the table grows to millions of rows, executing multiple JOIN operations introduces significant overhead, leading to high database load and slower query response times.
To handle these scenarios, the SeekTable reporting engine supports the configuration of Conditional JOINs to generate more optimized SQL queries and avoid unnecessary JOINs:
- for Select Query use simply:
SELECT o.* from orders o
- add a JOIN rule:
JOIN SQL To Apply For LEFT JOIN countries c ON (c.country_id=t.country_id)
Important: uset.prefix to refer to a column from the main (facts) table, regardless of what is specified in the Select Query.Select Query
Determines the target for the JOIN (see explanation below).c.country_name
Names of one or more dimensions that require this JOIN to resolve their values. Measure's parameter also can be specified here (applicable only for To=Select Query). - add a Dimension:
Type Name Parameters Fieldc.country_name
Refers to the column in joined table.Depends on the To option in the JOIN rule: Select Query: do not use parameters, or you can specify a custom SQL expression that usesc.country_nameif needed.GROUP BY Result: specifyo.country_idto use it as grouping criteria and resolve dimension's values from joined table.
The conditional JOIN may be used in the final query in two ways depending on the To choice in the JOIN rule:
Select Query- the JOIN is added to the main query that retrieves data and joined table columns can be used both for dimensions and measures.
GROUP BY Result- alternatively, the JOIN can be added to the outer query that retrieves aggregated data, and joined table columns can be used only for dimensions (not for measures). It is important to use this target only for 1:1 lookups (when joined table has unique index on the JOIN key) because otherwise it can lead to incorrect results due to data duplication after JOIN.
Enable totals for "FirstValue" measures
To get totals for measures defined with a custom SQL expression you can check Use "GROUP BY CUBE" option if
your DB supports this SQL syntax (MySql doesn't) and columns used as dimensions are not nullable.
For "GROUP BY CUBE" query database adds additional rows for subtotals where NULL values are used for grouping columns.
If your columns have NULL values
you need to use another value instead; to do that you may define a custom SQL for the dimension, for example:
COALESCE(column,'')(supported in all databaseses)ISNULL(column,'')(SQL Server)IFNULL(column,'')(BigQuery, Snowflake)
One more limitation is usage of pivot table's Filter: by default it is applied to aggregation results and since SeekTable engine cannot calculate "FirstValue" totals you still can get empty totals when this kind of table filtering is used. To handle this you can:
- use only report parameters ("Params" tab) to filter the report. Report parameters are applied in the DB query and when they are changed a new DB query is executed and totals are re-calculated on the DB side.
- enable Apply pivot table filter as a condition parameter option in the cube config.
When this option is enabled SeekTable tries to translate Filter into DB conditions so they work like report parameters.
Database-calculated totals will be shown only when all filters are translated to the DB query conditions:
- always use dimension's name hint in Filter
- prefer to use equality comparison, for example:
year=2019instead ofyear:2019 - string-contains comparison (for example:
name:"John") is translated only when Translate LIKE conditions is enabled
"FirstValue" measure + "Expression" dimension
When a measure is calculated with a custom SQL, the engine cannot perform roll-ups and this leads to some limitations in "Expression"-type dimensions usage. In particular, dimension's formula should produce a 1:1 projection - in other words, unique set of arguments should lead to an unique expression evaluation result (otherwise report can display zeros/empty cells).
Group by Range
Range grouping is a technique used in pivot tables to group numerical data into ranges. This is useful when you want to summarize large amounts of data into smaller, more meaningful categories.
For example, let's say you have a dataset containing the ages of customers. You could use range grouping to group the ages into categories such as 18-24, 25-34, 35-44, and so on.
To configure range grouping in SeekTable you need to add a new dimension (say, "Age (ranges)") and define it as an SQL expression that calculates groups according to your requirements:
- Dimension Name=
age_ranges - Dimension Type=
Field - Parameters: one entry with an SQL expression like that:
case when age between 0 and 18 then '0-18' when age between 19 and 60 then '19-60' else '60+' end
In a similar way you can define custom groups even for non-number columns (collapse several values into a one special group).