Search-driven analytics with natural language queries
Search-driven analytics is a new way how you can make ad-hoc queries and get answers simply by entering a natural language question. NLQ is particularly effective for enabling non-IT users in your company to make data-driven decisions: they don't need to understand pivot tables or data visualization, as reports are automatically configured through natural language search.
Ask questions to create pivot tables
LLM-powered cube's Ask Data and top-menu Search Box allow users to start data exploration with simple free-form queries. SeekTable automatically generates appropriate tabular report/chart based on the natural language query, providing clear and understandable answers. How it works:
- The user types a free-form query in plain English (or his native language) at the cube view.
- SeekTable composes a prompt context: a list of available dimensions/measures, values of certain dimesions (you can configure which dimensions to match at the cube configuration form) and cube's description
that can contain special
<prompt>tags with special instructions for LLM - so you can fine-tune Ask Data recognition for your concrete cube. - For the composed prompt, LLM outputs most relevant pivot table or flat table configuration.
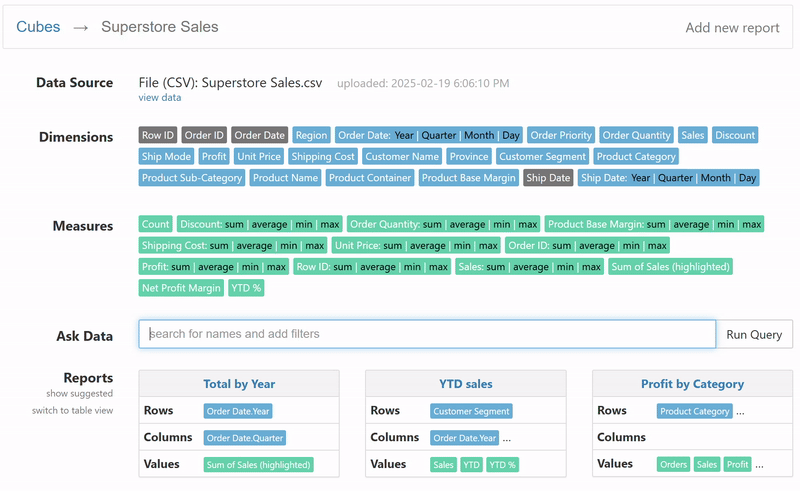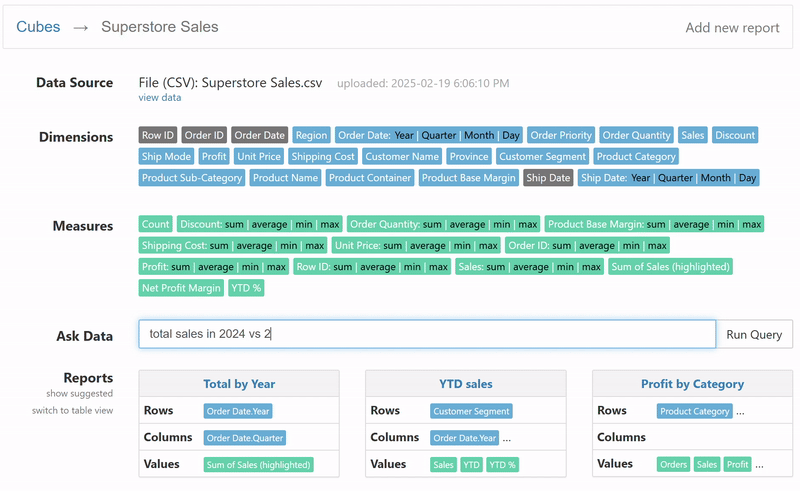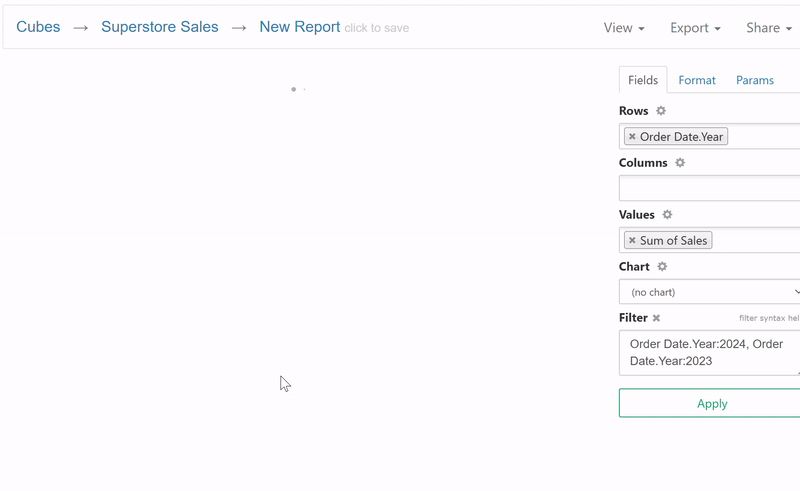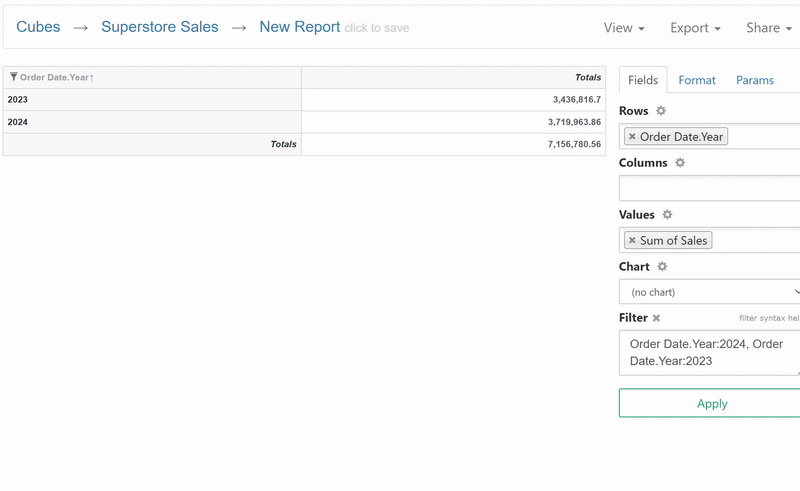
If proposed report looks good, the user can proceed to the report builder, or modify his query and try again.
Cloud SeekTable uses Gemini, self-hosted SeekTable can use any OpenAI-compatible LLM API. - Keep in mind that Ask Data is limited to answering questions based on your cube model and presenting the results in a table format.
Search-driven reporting significantly lowers the barrier to entry for data analysis. Try these online demos:
-
American Time Use Survey dataset:
type
average television by age range and gender -
Superstore Sales dataset:
type
show sales sum in 2024 vs 2023 by region and month
Sometimes you can get something different from what you expect; in this case you may back to your query by returning to the cube view ("back" in a web browser or click the cube name in the breadcrumbs) and clarify your question.
Search-driven reporting is enabled by default for all cubes but can be disabled if needed (via cube's configuration form).
Ask your report
This is another LLM-powered AI function designed to help users analyze their tabular reports.
Finding insights or anomalies in large tables requires concentration and attention.
Users can simply use the AI menu to run predefined report prompts or ask their own specific questions.
The Ask Report function isn't just for data analysis: you can ask the LLM to process your tabular data and generate a desired output. This feature can be especially useful for reports that contain unstructured text content.
It's important to remember that report prompts only have the data you currently see on the screen. Therefore, it's useless to ask questions that the current report can't answer.
Non-LLM "Ask Data" implementation
On-prem SeekTable installations without activated "AI Functions" have limited Ask Data that fallbacks to non-LLM search query recognizer (built-in / doesn't use any external APIs). This implementation works like a text search engine: it simply tries to find best matches of dimensions/measures for keywords from the query.
Note that non-LLM "Ask Data" does not really understand your query (intent) like LLM, it just matches keywords you entered and tries to suggest most relevant reports.
Keywords recognized in non-LLM search query parser:
- Dimension Names
- Word or phrase that matches dimension Label (or Name if label is not defined). Words order is not important.
- Measure Names
- Word or phrase that matches measure Label (or aggregate column name + measure Type if label is not defined).
Word order is not important; for example, if you have "Sum" measure for column "Total" you can reference it either with
total sumorsum of total. To use first "Sum" measure it is enough to specify justsum. - Hinted Comparison
- To filter by some dimension's value you may specify a hint keyword that refers to the dimension (or measure) before an entity name to clarify which exactly dimension (or measure)
you want to match. For example:
city Berlin(orcity:Berlin),name John. Hint is required if you want to filter by a high-cardinality column (when SeekTable cannot recognize a value). - Entity Name
- You can use specify full or partial name of some entity (company, person name, country, city etc) without a hint and
SeekTable will try to match most appropriate dimension that corresponds to this name.
For example:
Canada,New York,John Smith,closed(may refer to 'state' or 'status' column).Entities recognition works differently for CSV and databases. In case of CSV data SeekTable performs quick scan of CSV file and suggestions/by-value-recognition works for all dimensions. However, this approach is not possible for DB cubes, and suggestions/by-value-recognition works only for dimensions explicitly specified in "Match Dimension" list on the cube configuration form. It is recomended to specify here only low-cardinality dimensions that may be quickly loaded.
- Equality
=,equal,equals,not equal,not equals- Less Than
<,before,below,less,less than,fewer,under,ending with- Greater Than
>,after,after,above,greater,greater than,more,more than,larger,over,starting with- Dates
- SeekTable recognizes dates written in many different formats; this can be even incomplete date like
May 1or2019 Mar. Note that these 'partial' dates are applied correctly only when your cube has separate dimensions for date parts (year, month, day). - Relative Dates
yesterday,today,tomorrow,this month,current month,prev month,previous month,last month,next month,this year,current year,prev year,previous year,last year,next year