CSV pivot tables
CSV (or TSV) file is a simplest data source in SeekTable: it is enough to click Upload Data, choose a local file, and wait until file is uploaded. That's all: now you can create summary report (pivot table, chart) or review/filter/sort CSV data rows with a grid-view ('flat table').
All parameters are detemined automatically:
- CSV separator: comma, semicolon, pipe or tab. If separator auto-detection fails it is possible to specify it explicitely by placing
sep=,in the first line. - File encoding: UTF-16, UTF-8, Windows-1252, Windows-1251/KOI8-R (Cyrillic), Windows-1253 (Greek), ISO-2022-JP, ISO-2022-KR, ISO-2022-CN and others.
- First row should contain column names. If your CSV file doesn't contain headers row you have to add it.
- Data types: string, number, date. Other types may be parsed with custom expressions.
- For number columns sum/average/min/max measures are suggested.
- For date columns 3 date-part dimensions (year, month, day) are configured automatically.
- For a multi-value CSV column (that contain multiple values separated with a semi-colon) an additional dimension with
(Split)suffix is configured automatically. If engine doesn't detect some column as multi-value (this may happen if first CSV rows doesn't contain multiple values for that column) it is possible to setup(Split)dimension explicitely. - Columns with many unique values (IDs, number values) are configured as "flat-table only" dimensions. You can enable them for pivot tables if needed by editing the cube configuration.
CSV file may be compressed with zip or gzip, and this is only option if you want to upload large CSV file that is greater than upload limit (50Mb). Uncompressed CSV size might be up to 500Mb; SeekTable works fine with files of this size and pivot table generation should not take more than 5-10 seconds.
It is possible to define special expressions for custom handling of CSV values (parse timespans, apply replace rules etc).
To use a set of columns as values in reports an unpivot operation may be configured.
Refresh CSV data
In some cases you might need to refresh saved pivot table reports by uploading a newer version of the dataset. This is possible in the following ways:
- Manual
-
If CSV file name is the same as previously uploaded file: just upload new file and choose Refresh Existing Cube in the confirmation dialog.
Otherwise:
-
Determine GUID of the CSV-based cube you want to refresh; this value is present in the URL you see in the browser's address bar, for example:
https://www.seektable.com/cube/feb3828c57474791a5ee92b83d4195e0
In this case cube ID isfeb3828c57474791a5ee.92b83d4195e0 -
Rename new CSV file and use cube ID as file name. For example:
mydata.csv→feb3828c57474791a5ee92b83d4195e0.csv
mydata.zip→feb3828c57474791a5ee(if CSV file is zipped)92b83d4195e0.zip - Upload renamed file in a usual way (with Upload Data button).
- Instead of creating new cube SeekTable will replace old CSV file with a new version. All saved reports will be refreshed.
-
Determine GUID of the CSV-based cube you want to refresh; this value is present in the URL you see in the browser's address bar, for example:
- Automated
-
- Use Zapier and create a task to automate CSV data refreshes. For example, you can refresh reports each time when you change a Google Sheets document or a CSV file on Google Drive / OneDrive / Dropbox.
- Use Microsoft Power Automate for the same purpose.
- Use curl command-line tool:
curl -k -F "file=@sales.csv" -H "Authorization: YOUR_ACCOUNT_API_KEY" \ https://www.seektable.com/api/cube/import/csv?cubeId=CUBE_IDwhere sales.csv is a path to the local CSV file, YOUR_ACCOUNT_API_KEY is an API key value from "Manage Account" → "Get API Key", CUBE_ID is GUID of the cube to refresh.You can use curl to refresh reports on a schedule with help of Task Scheduler (on Windows) or cron (on Linux or MacOS).
Note: data refresh is possible only if new CSV file has the same columns as in old version of CSV file (with the same names, new columns are OK).
Calculated columns row-level expressions
It is possible to define expression-based (calculated) dimensions that are evaluated before aggregation step (on row-level). For example, if you have date column (say, "Some Date") it is possible to calculate quarter or day-of-week in the following way:
- add new dimension with Type=
Field - fill Name with some unique value: say, "Some Date (Quarter)" or "Some Date (DayOfWeek)"
- add a 1st Parameter which should be an expression (syntax is the same as for calculated members), for example:
Date.Quarter(Column["Some Date"])(quarter number 1-4)Column["Some Date"]!=null ? Column["Some Date"].DayOfWeek : null(day-of-week number 0-6) + Format={0:ddd}(0=Sun, 1=Mon, 2=Tue etc) or{0:dddd}(0=Sunday, 1=Monday, 2=Tuesday etc)Date.Week(Column["Some Date"])(week-of-year number)
Parameter["param_name"]; in particular, it is possible to define a special dimenion for dynamic grouping criteria that depends on the user's choice, for example:Parameter["dimension_name_param"]!=null ? Column[ Parameter["dimension_name_param"] ] : "-- choose a dimension --"
Column is a special variable that provides access to the context CSV row values; you can use column name directly
if it doesn't contain spaces or special symbols - for example, SomeDate. More details about expression syntax you can found
here.
Measures setup
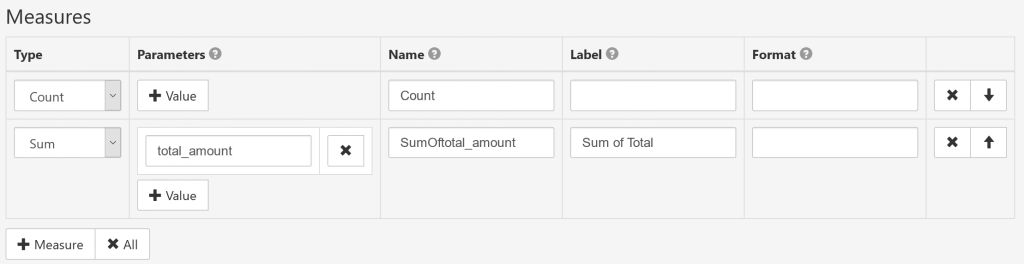
- Type
-
Count: the number of aggregated rows.
Sum: the total sum of a numeric column.
Average: the average value of a numeric column.
Min: the minimal value of a column.
Max: the maximum value of a column.
Count Unique: the number of unique or distinct values of a column.
Quantile/Median: 2-quantile value (median) for the a numeric column.
Mode: the value that appears most often.
Variance: the variance Var(X) of a numeric column. It is possible to calculate sample variance / standard deviartion / sample standard deviation by specifying 2-nd parameter for this measure type.
Expression: measure defined as formula calculated by SeekTable.
- Parameters
-
For Type=
Count: no parameters needed.
For Type=Sum/Average/Min/Max/Count Unique/Mode: name of CSV column to aggregate.
For Type=Quantile/Median: first parameter is name of CSV column; second parameter is optional and represents percentile value (default value is 0.5 which gives median).
For Type=Variance: first parameter is name of CSV column; second parameter is optional and can be: Variance, SampleVariance, StandardDeviation, SampleStandardDeviation (if not specified "Variance" is assumed).
For Type=Expression: first parameter is an expression, and next parameters are names of measures used as arguments in the expression. - Name
- Explicit unique measure identifier. You can leave it blank (for any measure types except "Expression") to generate the name automatically.
- Label
- User-friendly measure caption (optional).
- Format
-
Custom format template (syntax is for .NET String.Format, only zero-index placeholder
{0}can be used). Examples:{0:$#.##}→ format number as $10.25 (or empty if no value){0:0,.0#}k→ show number in thousands with "k" suffix{0:0.#|k}→ if number>1000 shorten it with "k" suffix{0:0,,.0#}M→ show number in millions with "M" suffix{0:0.#|M}→ if number>1000000 shorten it with "M" suffix{0:0.#|kMB}→ shorten large number with appropriate "k"/"M"/"B" suffix
Report parameters setup
You can define report parameters to specify report-specific filtering condition by CSV column(s) in Filter Expression:
- Name
- Unique (for this cube) parameter identifier.
- Label
- User-friendly parameter caption for UI (optional).
- Data Type
-
String: text-based value.
Int32: 32-bit integer (max value is 2,147,483,647).
Int64: 64-bit integer (max value is 9,223,372,036,854,775,807).
Decimal: Fixed-point number with max 28 significant digits. Decimal point is '.' character.
DateTime: date or datetime value (in case of date this will be datetime value with 0:00:00 time). Date value should be specified as string in YYYY-MM-DD format.
Boolean: accepts only 'True' or 'False' value.
- Multivalue
- If checked parameter can accept several values (as array, in UI user can enter them as comma-separated string). Multivalue parameter can be used only with IN condition.
- Default Value
- Defines default value of this parameter. Empty means 'not defined'.
- Expression
- Custom expression to evaluate final parameter value. Expression syntax is the same as in
calculated cube members; you can access user-entered values with
Parameter["param_name"].
For example:"%"+Parameter["param_name"]+"%"(wrap with '%' for 'like' condition).
When parameter is defined it can be used in Filter Expression as following:
"1"="1" @paramName[ and "csv_column_name":field="{0}":var ]
In this sample parameter name is paramName and CSV column to filter is csv_column_name.
Always-true condition "1"="1" is used to simplify conditions conjunction (it is enough to start parameter template with and).
Parameter placeholder syntax:
@- identifies that this is a placeholder for the parameter
paramName- parameter's Name
[ ]- expression between square brackets is added to Filter Expression when parameter is defined.
Optionally you may define a part that is added when parameter is not defined in this way:
@paramName[ expression_when_defined ; expression_when_NOT_defined ]
"{0}":var- placeholder for the parameter value.
{0}inserts the parameter name → that gives"paramName":varwhich refers to the parameter value.
Filter Expression syntax:
- condition syntax:
"csv_column_name":field <condition> "value"[:datatype]
- csv_column_name
- Name of the CSV column to filter. Expression-type dimension name cannot be used here.
- condition
<,<=,>,>=,=,!=,like,in. 'Like' works like in SQL: prepend/append '%' for 'contains' (you can add '%' automatically with help of parameter's Expression).- value
- hardcoded constant like
"Test", or parameter name with a 'var' datatype:"param_name":var - datatype
string,int32,int64,decimal,double,datetime
- boolean and/or operators:
C1 and C2,C1 or C2,C1 or (C2 and C3)
Manual multi-value columns setup
In most cases SeekTable detects a multi-value column automatically and adds a special <column_name> (Split) dimension.
If this detection fails you still can manually configure multi-value handing for the column in this way:
- Go to CSV cube configuration form
- For the dimension that corresponds to a CSV column with multiple values add to Parameters:
{"Multivalue":true, "MultivalueSeparator":";"} -
Add a one more dimension with Name=
<column_name> (Split)(exactly one space should be between a column name and the suffix).
Define column's datatype explicitely
CSV files don't specify data types for columns and SeekTable have to determine these data types automatically (by analyzing first N rows of the dataset). In most cases this autodetection works well, however in some cases column's data type may be incorrectly detected:
- many first rows have empty-string values for that column: can be detected as
Stringtype, but in fact it may contain numbers or dates. - first rows of that column contain empty or number values, but then non-number values go later: can be detected as
Integer(so all non-numbers are ignored), but in fact this should beString.
To handle that you may explicitely define column's data type in this way:
- Go to CSV cube configuration form
- Find a dimension with name that corresponds to an appropriate CSV column and add this into Parameters:
{"ValueTypeCode":"String"}Another type codes that may be specified:Int32,Decimal,Double,DateTime,Boolean.
Accelerate CSV data queries with DuckDB
If your CSV file is not small (say, larger than 10Mb) you may experience some delays in report generation.
In this case, it makes sense to check Accelerate queries with DuckDB when possible (cube form option) which
can delegate CSV data processing to the built-in DuckDB engine; this can get improve CSV data queries in 10x+ times.
Note that DuckDB acceleration is possible only when (these constraints are checked automatically):
- CSV file encoding is UTF-8, UTF-16 or ASCII
- Report doesn't use unpivot dimensions
- Report doesn't use dimensions with row-level expressions
- Report displays only measures from this list:
Count,Sum,Min,Max,Average
How to use Excel/JSON data or multiple CSV files
If your data is not in CSV format you can easily convert it to CSV using (free) command line tools like csvkit or xsv. For example:
- Convert JSON to CSV using csvkit:
in2csv data.json > data.csv. - Convert Excel to CSV using csvkit:
in2csv data.xls > data.csv. - In a similar way you can pre-filter your data, slice it or merge multiple CSV files into one CSV and then upload it to SeekTable.
Alternatively, you may use SQL to query Excel/JSON/multiple CSVs with the help of built-in DuckDB engine (self-hosted SeekTable only).
How to analyze large CSV files
In case if you want to create a pivot table by a CSV file that exceeds upload limit (even when compressed) you still can do that in one of the following ways:
- Consider to use self-hosted SeekTable that allows to upload CSV files of any size. Enable DuckDB acceleration option.
- You may query really large CSV (JSON, Parquet, Excel) files like SQL tables via built-in DuckDB engine (available only in on-prem SeekTable).
- Finally, you may import your CSV data into a database that is supported as a data source by SeekTable; for medium-size datasets PostgreSql can be a good choice (for importing CSV data you can use csvkit mentioned above), for large/big data (many millions / billions of rows) it makes sense to use specialized solutions like Google BigQuery, Amazon Redshift or ClickHouse (this one is a free/open-source product). If your dataset has a lot of unstructured data (text content) and you want to filter by this text content (quickly) ElasticSearch can be a good fit.