ElasticSearch connector for pivot tables, charts
With built-in ElasticSearch connector SeekTable can use your indexes as a data source for data exploration and reports generation. SeekTable works with ElasticSearch as with an OLAP (live) data source: ES queries are generated automatically, no need to write Elastic Query DSL by hands. This also means that reports - pivot tables/charts/datagrids - always display actual data loaded from ES indexes in the real-time. SeekTable can used as a complementary BI tool (in addition to Kibana/Grafana) for:
- advanced pivot tables / tabular reports
- work with Elastic indexes as data tables (in terms of columns and rows) for ad-hoc queries by non-tech users
- publish/embed live ElasticSearch reports: pivot tables may be displayed in existing Kibana or Grafana dashboards or integrated into any web application via iFrames
There is no limitations on the ElasticSearch index size and reports generation performance primarily depends on the power of your ElasticSearch cluster.
How to configure ElasticSearch data source
- Click the "Connect to Database" at "Cubes" view, or just open this link (ensure that you're logged in).
-
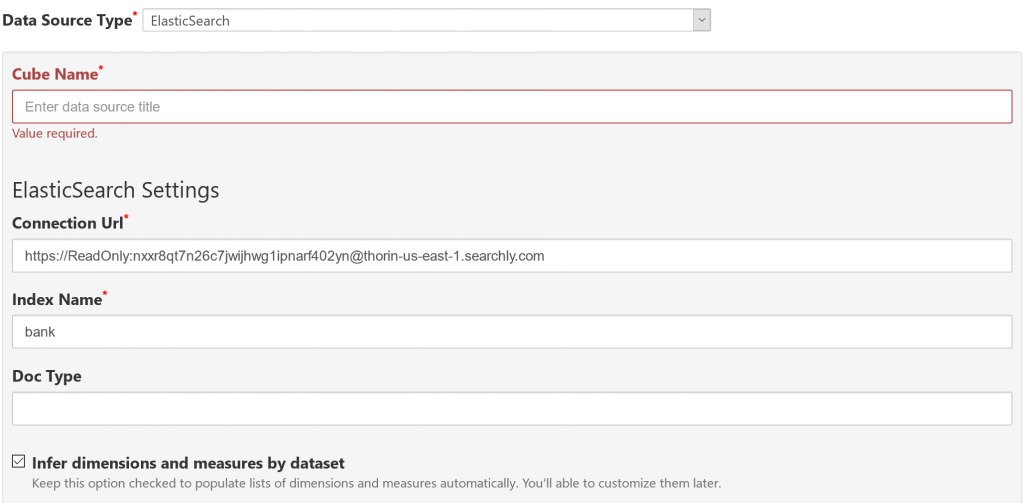
Select "ElasticSearch" in Data Source Type selector:
-
Please fill out all required fields:
- Cube Name
- short title that describes this data source
- Connection URL
-
Base URL of your ElasticSearch API endpoint, for example:
https://ReadOnly:nxxr8qt7n26c7jwijhwg1ipnarf402yn@thorin-us-east-1.searchly.com
- Index
- the name of the index to query. In ElasticSearch you can query multiple indexes, so you can specify them as
index1,index2or use wildcards likelogs-2018-*. - Doc Type
- you might need to specify mapping type if you use legacy version of ElasitcSearch (5.x or earlier). For ElasticSearch 6.x (or higher) no need to specify doc type option.
- Filter Expression
- here you may define filtering conditions for Elastic query with SQL-like syntax, for example:
timestamp >= "2018-10-20":datetime
- condition syntax:
"field_name":field <condition> "value"[:datatype]
- field_name
- Name of the ES document field to filer.
- condition
<,<=,>,>=,=,!=,like,in. 'Like' works like in SQL: use '%' to specify starts-width/ends-with/contains match. When 'like' is used with a report parameter '%' can be added automatically with help of parameter's Expression.- value
- hardcoded constant, or parameter name with 'var' datatype:
"param_name":var - datatype
string,int32,int64,decimal,double,datetime
- boolean and/or operators:
C1 and C2,C1 or C2,C1 or (C2 and C3)
- condition syntax:
- Infer dimensions and measures by columns option: keep it checked to determine dimensions and measures by first N documents - in this case you don't need to define Dimensions and Measures by yourself. You can edit configuration later and remove excessive elements, or customize automatically determined ones.
- Click the "Save" button.
If everything is fine you should see a new cube dashboard with the list of available dimensions/measures.
In case of connection error you'll see an orange box with the error message; don't forget to ensure that ElasticSearch API can be accessed by SeekTable server and it is not blocked by firewall.
If you specified "Infer dimensions and measures" option and get a cube with no dimensions most likely you've specified non-existing mapping type in "Doc Type".
Dimensions setup
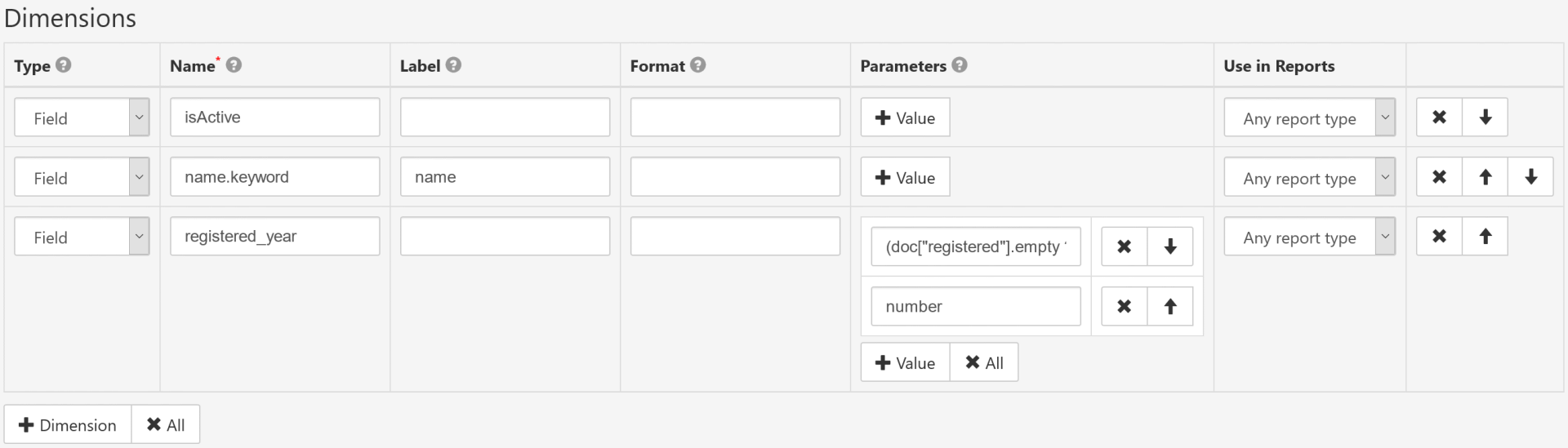
- Type
-
Field: dimension value is resolved from ES query result: a document field, script field (when script code is provided in "Parameters") or bucket aggregation definition (when bucket aggregation JSON is provided in "Parameters").
Expression: dimension is defined as calculated field with custom formula that uses another dimensions as arguments (formula and arguments should be specified in "Parameters"). - Name
- Unique dimension identifier. For Type=
Fieldthis is document or sub-document field specifier. - Label
- User-friendly dimension title (optional).
- Format
-
Custom format template (syntax is for .NET String.Format, only zero-index placeholder
{0}can be used). Examples:prefix {0} suffix→ append custom prefix and/or suffix{0:yyyy-MM-dd}→ format date (or timestamp) as 2017-05-25{0:MMM}→ format month number (1-12) as a short month name (Jan, Feb etc){0:MMMM}→ format month number (1-12) as a full month name (January, February etc){0:ddd}→ format day-of-week number (0-6) as a short day-of-week name (0=Sun, 1=Mon, 2=Tue etc){0:dddd}→ format day-of-week number (0-6) as a full day-of-week name (0=Sunday, 1=Monday, 2=Tuesday etc)
- Parameters
-
Type=
Field:-
first parameter can be a custom script field with "painless" expression syntax.
For example:
(doc["registered"].empty ? null : doc["registered"].date.year)
(extracts year value from "registered" date field). Second parameter is optional and declares data type of the script result: "string" or "number" (this affects sorting by this dimension). - first parameter can be a JSON definition of ES bucket aggregation.
For example:
{ "histogram": {"field":"age","interval":5} }
Type=
Expression: you can specify formula expression (1-st parameter) and dimension names for the arguments (2-nd, 3-rd etc parameter). -
first parameter can be a custom script field with "painless" expression syntax.
For example:
Date-part dimensions calculated with painless expressions
To define date-part dimensions (date's "year", "month", "day" etc) you may add dimensions defined with an appropriate ES expression (painless):
- add new dimension with Type=
Field - fill Name with some unique value: say, "date_field_year"
- add 1st entry to Parameters:
- For year:
(doc["date_field"].empty ? null : doc["date_field"].value.year) - For month:
(doc["date_field"].empty ? null : doc["date_field"].value.monthOfYear)+ Format={0:MMM}(Jan, Feb etc) or{0:MMMM} (January, February etc) - For day:
(doc["date_field"].empty ? null : doc["date_field"].value.dayOfMonth) - For day-of-week:
(doc["date_field"].empty ? null : doc["date_field"].value.dayOfWeek)+ Format={0:ddd}(0=Sun, 1=Mon, 2=Tue etc) or{0:dddd}(0=Sunday, 1=Monday, 2=Tuesday etc)
- For year:
- add 2nd entry to Parameters:
number
Measures setup
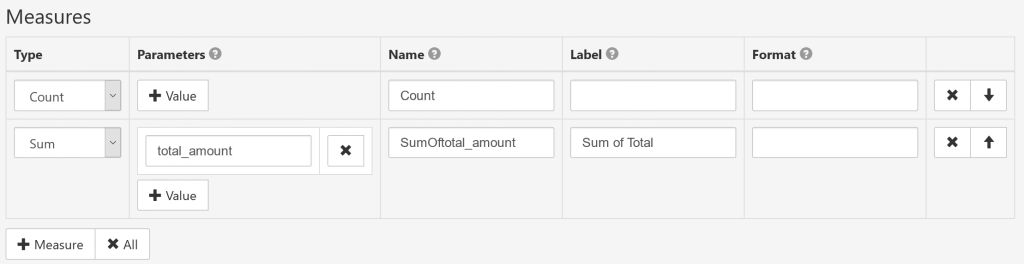
- Type
-
Count: the number of aggregated documents.
Sum: the total sum of a numeric field.
Average: the average value of a numeric field.
Min: the minimal value of a column.
Max: the maximum value of a column.
FirstValue: custom ES aggregate type definition.
Expression: measure is defined as a calculated field.
- Parameters
-
For Type=
Count: no parameters needed.
For Type=Sum/Average/Min/Max: document field or field path to aggregate.
For Type=FirstValue:- first parameter is a custom definition of
ES metric aggregation JSON. For example:
{ "extended_stats": {"field":"balance"} } - second parameter is optional and declares metric value in ES result ("value" is used if not defined).
If first parameter defines multi-value ES metric calculation (like "extended_stats") 2-nd parameter is required; for example:
std_deviation
Expression: first parameter is a formula expression, and next parameters are names of measures used as arguments in the expression. - first parameter is a custom definition of
ES metric aggregation JSON. For example:
- Name
- Explicit unique measure identifier. You can leave it blank (for any measure types except "Expression") to generate the name automatically.
- Label
- User-friendly measure caption (optional).
- Format
-
Custom format template (syntax is for .NET String.Format, only zero-index placeholder
{0}can be used). Examples:{0:$#.##}→ format number as $10.25 (or empty if no value){0:0,.0#}k→ show number in thousands with "k" suffix{0:0.#|k}→ if number>1000 shorten it with "k" suffix{0:0,,.0#}M→ show number in millions with "M" suffix{0:0.#|M}→ if number>1000000 shorten it with "M" suffix{0:0.#|kMB}→ shorten large number with appropriate "k"/"M"/"B" suffix
Note: totals/sub-totals will be empty for FirstValue measures.
Report parameters setup
Report parameter allows you to specify some filtering condition in ES query by user-entered value. Typical usage of report parameters:
- filter by the field that is not used in the report
- filter data in ElasticSearch query for pivot tables
- published reports: define how viewers can filter report data
- Name
- Unique (for this cube) parameter identifier.
- Label
- User-friendly parameter caption for UI (optional).
- Data Type
-
String: text-based value.
Int32: 32-bit integer (max value is 2,147,483,647).
Int64: 64-bit integer (max value is 9,223,372,036,854,775,807).
Decimal: Fixed-point number with max 28 significant digits. Decimal point is '.' character.
DateTime: datetime or date value (in this case datetime value has 0:00:00 time). Date value should be specified as string in YYYY-MM-DD format.
Boolean: accepts only 'True' or 'False' value.
- Multivalue
- If checked parameter can accept several values (as array, in UI user can enter them as comma-separated string). Multivalue parameter can be used only with IN condition.
- Default Value
- Defines default value of this parameter. Empty means 'not defined'.
- Expression
- Custom expression to evaluate final parameter value. Expression syntax is the same as in
calculated cube members; you can access user-entered values with
Parameter["param_name"].
When parameter is defined it can be used in Filter Expression as following:
"1"="1" @paramName[ and name.keyword="{0}":var ]
Parameter placeholder syntax:
@- identifies that this is a placeholder for the parameter
paramName- parameter's Name
[ ]- expression part between square brackets is added to Filter Expression when parameter is defined.
"{0}":var- an inner placeholder for the parameter's value.
In this sample parameter name is paramName and ElasticSearch document field to filter is name.keyword.
Display array field as a single value
If your index contains multi-value field like this:
{
"categories" : ["A", "B"]
}
and you want to display this array as a 'joined' string value this is possible by adding a dimension evaluated with "painless" script expression:
- Name:
categories_joined - Parameters:
(doc[\"categories.keyword\"].join(\",\"))
Now "categories_joined" dimension can be used both in pivot-table and flat-table reports to display array values, i.e. A, B.
Troubleshooting
some_text_field] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.
This error appears when you try to aggregate by text field and your ElasticSearch index doesn't have original values for this field.
In most cases you can use .keyword suffix and enable unindexed values for aggregation as described in
official ElasticSearch documentation.
some_painless_script_expression)
This error happens when ElasticSearch cannot evaluate calculated field defined with painless expression.
Typical case is when date values are stored as strings in format that is not recognized as
'Date' datatype
by ElasticSearch
and as result expression that takes part of the date (like doc["timespamp_field"].date.dayOfMonth) fails.
To fix this you need to define a mapping for this field that declares Date datatype and formats to match (if needed).
some_keyword\"" }): ElasticSearch query
You may get an error like this ('caused_by' may be a bit different) with flat table report type and when you specify
a keyword to filter without field name hint: in this case SeekTable produces OR condition for all fields selected as columns,
and one of them is not comparable with the specified keyword value.
Workaround: specify a hint for the keyword in the filter, for example: name:John.
This may happen when you selected high-cardinality field in the pivot table report. To fix this you can use report parameter(s) to apply some filtering condition in ElasticSearch query. If you need to get more than 10k unique values in the pivot table you'll need to change [search.max_buckets] option in your cluster level setting.