PostgreSql BI Tool for pivot tables, charts, tabular reports
SeekTable is a business intelligence tool that can make PostgreSQL data available for all employees - both technical and non-technical - to query, explore, and report on. With SeekTable you can automate PostgreSql reports generation and deliver them on schedule.
SQL-compatible data source supports official PostgreSql client which is suitable for connecting to Amazon Redshift and databases that support Postgre-compatible interface (like QuestDB, Cube, Supabase).
-
PostgreSql is used as a live data source: no need to refresh reports as users always get actual data (direct query mode).
This means that your PostgreSql server should be able to execute aggregate queries fast enough - ideally in seconds. Usually this is not a problem if configured query returns a reasonable number of rows; otherwise, you may try to configure report parameters to reduce data that needs to be aggregated or use pre-aggregated materialized views. For near real-time reporting on big tables PostgreSql data can be mirrored to specialized analytical columnar databases like TimescaleDB, ClickHouse or even DuckDB. - Reports may be shared with a team or published for embedding (or public link sharing). Users can subscribe to reports in a self-service manner.
- The cube itself may be shared too: users can create own reports without having direct access to PostgreSql database.
- Web API can be used for automated reports generation (export to Excel, multipage PDFs).
How to configure PostgreSql cube
- Click the "Connect to Database" to open a new data cube configuration form.
-
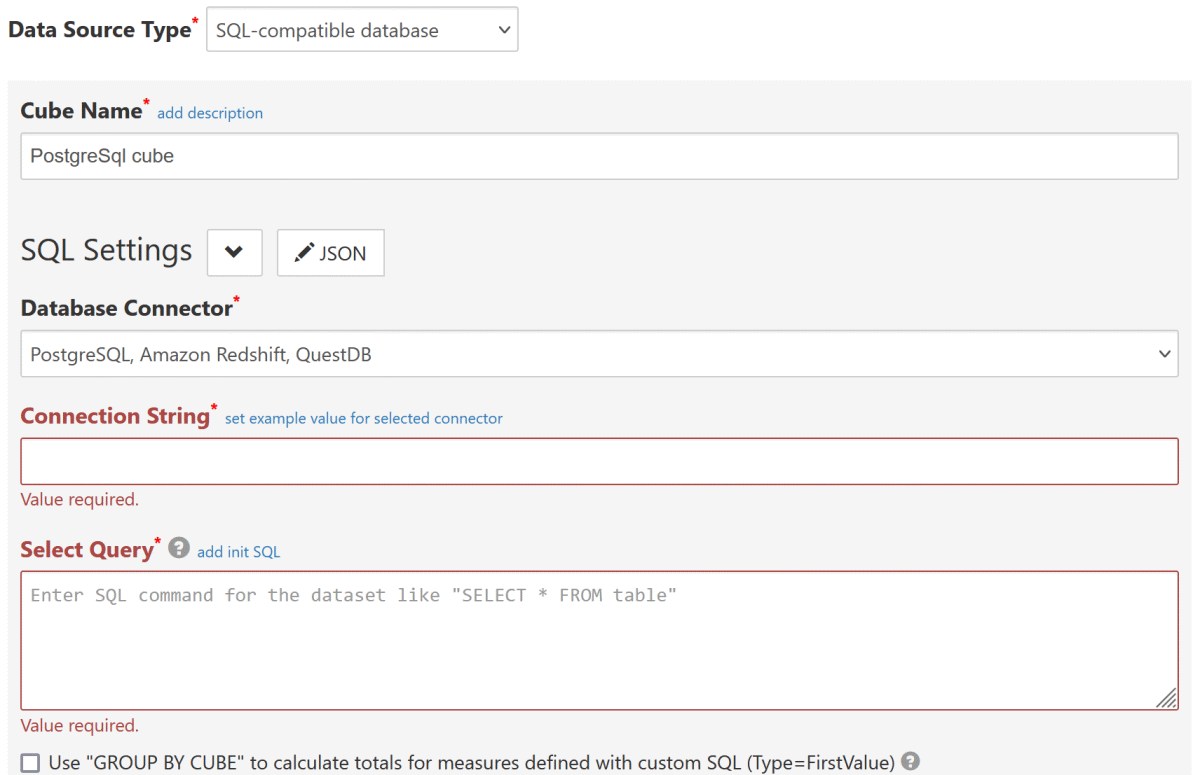
Choose Data Source Type:
SQL-compatible database(this opens SQL Settings section). -
Choose Database Connector:
PostgreSql, Amazon Redshift, QuestDB
-
Connection String should be a valid connection string for NpgSql driver. For example:
Host=hostName;Port=5432;Database=db;User ID=user;Password=password;
Host Specifies the host name of the machine on which the PostgreSql is running.
Do not use "localhost" or LAN server name; use only public IP address or server's domain name.Port The TCP port of the PostgreSQL server. Database The PostgreSQL database to connect to. User ID The username to connect with. Password The password to connect with. SSL Mode Specify SSL Mode=Requireto force SSL or if your PostgreSql allows only SSL connections.Trust Server Certificate Specify Trust Server Certificate=Trueto allow self-signed SSL server certificates.Server Compatibility Mode Specify Redshiftif your configure a connection to Amazon Redshift.
SpecifyNoTypeLoadingif your configure a connection to QuestDB or cube.js. - Configure other required settings as described in SQL-compatible data source. As a minimum you need to specify Select Query (which determine's the dataset) and keep Infer dimensions and measures by dataset checked.
Date-part dimensions calculated with SQL expressions
To define date-part dimensions (date's "year", "month", "day" etc) you may add dimensions defined with an appropriate SQL expression:
- add new dimension with Type=
Field - fill Name with some unique value: say, "date_column_year"
- add one Parameter which should be a date-part PostgreSql SQL expression:
- For year:
EXTRACT(YEAR FROM date_column) - For month:
EXTRACT(MONTH FROM date_column)+ Format={0:MMM}(Jan, Feb etc) or{0:MMMM} (January, February etc) - For day:
EXTRACT(DAY FROM date_column) - For day-of-week:
EXTRACT(DOW FROM date_column)+ Format={0:ddd}(0=Sun, 1=Mon, 2=Tue etc) or{0:dddd}(0=Sunday, 1=Monday, 2=Tuesday etc) - For quarter:
EXTRACT(QUARTER FROM date_column) - For week-of-year:
EXTRACT(WEEK FROM date_column)
- For year:
QuestDB notes
SeekTable can access QuestDB with Postgres wire protocol that is by default accessible via 8812 port. To configure a QuestDB-based cube choose PostgreSql as a database connector and specify a connection string like this:
Host=QUEST_DB_IP;Port=8812;Database=qdb;User ID=admin;Password=quest;ServerCompatibilityMode=NoTypeLoading;
To access QuestDB on "localhost" you can consider using a self-hosted SeekTable version (deployed with Docker).
Known limitations:
- Auto-generated dimensions for date-parts (year/month/day) use PostgreSql syntax and will not work in QuestDB. To fix that it is enough to use QuestDB-specific functions instead:
EXTRACT(YEAR FROM "column")→ YEAR("column")
EXTRACT(MONTH FROM "column")→ MONTH("column")
EXTRACT(DAY FROM "column")→ DAY("column") - GROUP BY CUBE syntax is not supported by QuestDB.
Cube.js notes
SeekTable can access Cube.js with Postgres-compatible protocol that is by default accessible via 5432 port. To configure a Cube.js-based cube choose PostgreSql as a database connector and specify a connection string like this:
Host=CUBE_JS_IP;Port=5432;Database=default;User ID=test;Password=test;Server Compatibility Mode=NoTypeLoading;
Known limitations:
- GROUP BY CUBE syntax is not supported by Cube.js (yet), so it is not possible to load custom-SQL measures (Type=FirstValue) with totals.
Supabase notes
Supabase provides connection pooling (shared pooler or dedicated pooler). This is managed by Supavisor (which includes PgBouncer) so you need to apply an appropriate NpgSql compatibility option in the connection string:
Pooling=false
Without this option your reports may 'stuck' on data load stage (looks like a connection timeout).
Troubleshooting
- Server certificate was not accepted or The remote certificate is invalid according to the validation procedure
- Add
Trust Server Certificate=Trueto the connection string to disable SSL certificate validation (needed if your server uses self-signed certificate). - ERROR: operator does not exist
- This error usually occurs with flat-table reports that have a filter for some column and data type of this column is not comparable with the specified value (PostgreSql uses strict typing).
To fix this you can cast the column to the datatype needed for the comparison. Typical cases:
- if error message contains "operator does not exist: text > numeric" (comparison may be different) and your filter is something like
some_column < 5this means thatsome_columnhas TEXT datatype. To fix this go to the cube configuration form, find the dimension with Name "some_column" and add a Parameter to define SQL expression with a cast:some_column::NUMERIC. - if error message contains "operator does not exist: date = text" and your filter is something like
some_column="2019-05-15"this means that column's data type is Date (or DateTime) and it cannot be compared with a TEXT value. To fix this go to the cube configuration form, find the dimension with Name=some_column and add a Parameter to define SQL expression with a cast; for example:some_column::date,some_column::timestamp.
- if error message contains "operator does not exist: text > numeric" (comparison may be different) and your filter is something like
- Out of the range of DateTime (year must be between 1 and 9999)
- This happens when "Select Query" returns a timestamp column with value(s) that cannot be represented by
.NET DateTime object (usually because of year part).
In some cases this may be fixed by adding
ConvertInfinityDateTime=Trueto the connection string; if this doesn't help you need to exclude unpresentable timestamps from the query results (either by WHERE filtering or by timestamp normalization with an SQL expression). - ERROR: The field 'some_column' has a type currently unknown to Npgsql
- This error occurs when "Select Query" returns a column that has a
data type that is unknown to Npgsql driver.
For example, this error may occur if you have a 'citext' column.
To fix this it is enough to cast this field to a known data type like::TEXT(custom SQL expression for the dimension may be specified in "Parameters").